

いよいよ今回より、「DOM」について見ていきます。
今まで、かなり深いところまで、JavaScriptの基本を学んで来ましたが、正直、一体何をするのかピント来ていない方が多いと思います。
HTMLやCSSのように、直感的に感じることが出来ないのが、JavaScripであり、途中で挫折してしまう方のほとんどが、何を学習しているのか分からないという理由で挫折してしまうのです。
しかし、ここまで我慢強く学習を続けて来られた方は、もう大丈夫だと思います。
これから少しずつですが、ウェブサイトと直接関連する内容を学習していきますので、今までよりも学習の楽しみが増えてくると思います。
(とは言っても、後もう少し概念的な学習が続くのですが、、、)
DOM
DOMとは
「DOM(Document Object Model)」は、HTML、XML、JSONなどを取り扱う「API(Application Programming Interface)」のことを言います。
APIとは、もの凄く簡単に言うと、外部のサイトからメソッドを使って連携できる仕組みのことになります。
DOMの操作には仕様書があり、それが「WHATWG」という団体によって管理されています。
なぜ「WHATWG」が標準になったのかなどについてご興味のある方は、JavaScriptの歴史などを調べてみてください。
また、「WHATWG」の内容については、以下のサイトで確認することが出来ます。

DOMは、HTML等(タグやテキスト)をオブジェクトとして扱います。
このオブジェクトを「ノード」と呼ぶこともあり、さらにタグを「要素ノード」、テキストを「テキストノード」などと分類することがあります。(ノードは全部で12種類あるようです)
そしてそれらが階層的(ツリー的)になっているものとして扱います。
とりあえず言葉で説明しましたが、分かりにくいと思いますので、以下詳しく見ていきましょう。
DOM ツリー
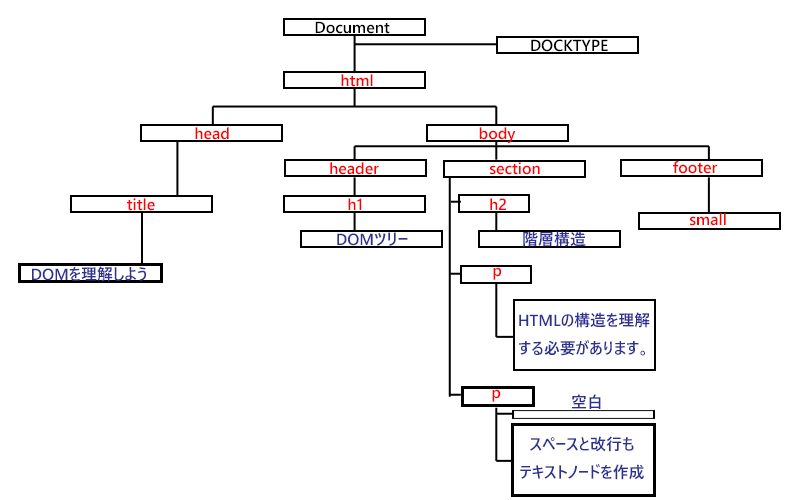
DOMはHTMLをツリー構造として認識しています。
一番最初にあるのが、「Document」でDOMの入り口になる部分です。
「ドキュメントノード」とも言います。
赤い文字で書いたタグが、「要素ノード」、青い文字で書いた部分が「テキストノード」になります。
改行やスペースもテキストノードとして認識されます。
また、ここでは書いてありませんが、コメント(JS内のコメント)も「コメントノード」として認識されます。
そしてこのツリーを見て思い出して頂きたいのが、「親子関係」です。
HTMLとCSSの学習が随分前だったので忘れてしまった方もいらっしゃるかと思いますが、ツリー構造で確認すると良く分かると思います。
(例、bodyは header と section と footer の親になります。)
getElement*
getElementById
document.getElementById (id)
HTMLのid属性を利用(引数に)して、要素ノードにアクセスすることが出来ます。
「getElementById」の大文字と小文字の区別に注意してください。
HTML
<body>
<h1 id = "sample"> getElementByIdを取得する </h1>
<p> いよいよHTMLと連携していきます。</p>
</body>
JS
let takeId = document.getElementById('sample');
takeId.style.background = 'red';

ここでは、id属性の「’sample’」を引数として指定し、背景色を変更しています。
HTMLで一つのページで、id属性の名前に同じものを使用してはいけない理由がここで明らかになったと思います。
同じidを複数持つ要素があったとしたら、どのように実行されるか分からなくなってしまいます。
getElementsByTagName
document.getElementsByTagName(tagname)
タグ名から要素ノードを取得します。
指定したタグはすべてのタグに一致します。
また、指定したタグ名を持つ要素の「HTMLCollection」を返します。
HTMLCollectionはオブジェクトであり、以下から構成されています。
- lengthプロパティ:要素数
- item(i)メソッド:i番目の要素
- namedItemメソッド:id または name属性が一致する要素
HTML
<h2>果物</h2>
<p>ばなな</p>
<p>りんご</p>
<p>ぶどう</p>
<p>オレンジ</p>
<p>いちご</p>
JS
let elements = document.getElementsByTagName('p');
console.log(elements);
console HTMLCollection(5) [p, p, p, p, p] 0: p 1: p 2: p 3: p 4: p length: 5
ページに含まれるすべてのp要素が取得されています。
プロパティやメソッドを使って、p要素のテキストを返してみましょう。
let elements = document.getElementsByTagName("p");
let leng = elements.length;
for (let i = 0; i < leng; i++) {
console.log(elements.item(i).textContent);
}
ばなな
りんご
ぶどう
オレンジ
いちご
「textContent」でテキストのみを表示させています。
ここではドキュメントを指定していますが、要素を指定することも出来ます。
その際はid属性を指定します。
「document」→ 「sample(id属性)」(getElementByIdのコードをご参照ください)
今までにご紹介した「ById」と「ByTagName」以外にも、「ByClass」、「ByName」があります。
基本的な使い方は、「ByTagName」と同じになりますので、割愛させて頂きます。
なお、これらは実際にあまり使われることのないものですので、お時間のある時に目を通すくらいで良いかと思います。
querySelector*
「querySelector*」は、CSSのセレクタ形式で条件を指定して、ノードを取得します。
CSSのセレクタ形式というのは、CSSを書く時に、HTMLのタグやid属性、class属性などスタイルを適用したい要素を指定する時に書く形式です。
あまり難しく考えずに、CSSを書いたときを思い出してください。
指定方法
let elements = document.querySelectorAll(‘*’);
すべての要素ノードを対象とする
let elements = document.querySelectorAll(‘p’);
タグを指定
let elements = document.querySelectorAll(‘idName’);
id属性の値を指定
let elements = document.querySelectorAll(‘className’);
class属性の値を指定
let elements = document.querySelectorAll(‘#idName, .className’);
id属性、またはclass属性など、複数の属性を指定
その他に、「#idName > p」や「#idName p」、擬似クラスなど、CSSのセレクタに使われるパターンが存在します。
querySelector
let elements = document.querySelector("p");
console.log(elements.textContent);
ばなな
「querySelector」は条件に一致する最初の要素を返します。
querySelectorAll
let elements = document.querySelectorAll("p");
let leng = elements.length;
for (let i = 0; i < leng; i++) {
console.log(elements.item(i).textContent);
}
ばなな
りんご
ぶどう
オレンジ
いちご
「querySelectorAll」は条件に一致するすべての要素を返します。
なお、「querySelectorAll」を使って、「querySelector」と同じ結果を得るには、以下のように記述します。
let elements = document.querySelectorAll("p");
console.log(elements[0].textContent);
ばなな
「[0]」で、インデックスを指定しています。
あとがき
DOMの概念について見てきました。
何となく分かっていたことを改めて確認すると、今までの散発的な知識がスッキリと頭に入ったような気がします。
これからしばらくはドキュメントに関連する内容を学習していきますので、分からなくなった時はこのページに戻って基本を思い出してください。
今回も最後までお読み頂きありがとうございました。

